
Modern applications often depend on resources and services from other services or systems, that may be hosted on the cloud, on a different machine, and in some other distributed architecture.
Sometimes, some of these services might not be reachable, due to momentarily network issues, processing load, or any other reason. This will affect your application or service if you depend on them. Requests might fail, get rejected or denied, and so on.
These errors or failures are often momentary, and the services get ‘back online and continue to respond to and process incoming requests. In this case, a ‘retry’ of the previously failed call will get a response back.
Adding a retry mechanism to your application makes it more resilient to such failures. So what is Resilience?
Resilience is the ability to recover from failures and continue to function. It isn’t about avoiding failures but accepting the fact that failures will happen and responding to them in a way that avoids downtime or data loss.
In this post, we will focus on handling such cases and failures from the code, using `Polly` – a transient fault handling NuGet library. It is worth mentioning that there are more ways to handle these cases, from outside the code, like LinkrdMesh and others, which we will not discuss here.
What is Polly?
Polly is a .NET resilience and transient-fault-handling library that allows developers to express policies such as Retry, Circuit Breaker, Timeout, Bulkhead Isolation, Rate-limiting and Fallback in a fluent and thread-safe manner
From Polly’s github (http://https://github.com/App-vNext/Polly)
How does Polly work?
Polly handles such transient errors described above, based on *Policies* that tell Polly what and how to handle these errors. These policies are defined usually during application startup and injected via dependency injection, or used directly from other services with factories.
Let’s take a look at some of the available Polly policies next.
Polly policies
Retry
If the fault is unexpected you can retry the request immediately or after a few seconds.
Waiting between retries: Waits for a configured time before sending the request again. Practices such as exponential backoff and jitter refine this by scheduling retries to prevent them from becoming sources of further load or spikes.
Circuit Breaker
A circuit breaker detects the level of faults in calls placed through it, and prevents calls when a configurable fault threshold is exceeded.
Polly
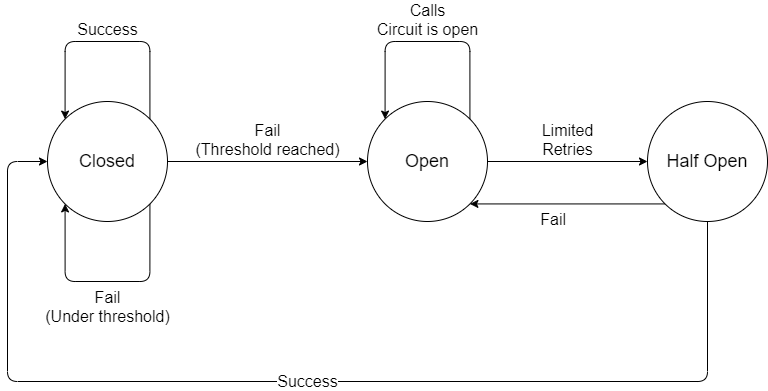
A Circuit breaker has three states:
- Closed: The circuit initially starts closed, the application works well and every request is sent. The state does not change even if you have many faults that exceed the threshold boundary.
- Open: the service is never invoked and the application fails immediately. This state has a definite period of duration before passing to the next state or directly to the Close state.
- Half-Open: a limited number of invocations of service is permitted. If any invocation has success the state pass to Close, on the other hand, if you get one error the state pass to Open
The circuit breaker policy might not be useful if you need to handle such fails in a certain manner. Cases like exceptions raised from local resources that need to be handled separately, might not be suitable for circuit breakers.
Fallback
The fallback policy lets you define how the application should handle the failure if, despite all retires, the operation has failed.
Timeout
This allows the caller to stop waiting for the response after a certain amount of time has passed. The network timeout policy supports two ways to timeout an executing call: Pessimistc and Optimistic.
The Optimistic strategy assumes that the executing code supports canceling an operation with a cancellation token.
The Pessimitic strategy assumes that the executing code may not honor the cancellation token. In this approach, the caller of the code is assumed to ‘walk away’ when a timeout happens, without waiting for the execution to complete, or handling a timeout. In this case, upon timeout, Polly captures and passes the abandoned execution to you as the Task parameter of the onTimeout/onTimeoutAsync delegate. (For more information refer to Polly’s documentation).
Bulkahead
The bulkhead policy is used to control and limit access to a resource by multiple (sometimes simultaneous) threads, to avoid overloading it and causing cascading failures in the system.
Combing Polly policies
The policies mentioned above provide us with the ability to address and handle failure in many ways, thus making our services and applications more resilient to failures. Combining these policies together gives us yet even more power and adds more resilience to our applications. In the next section, we will see how to combine Polly policies with PolicyWraps.
Implementing Polly in a .Net application
Step 1: Install Polly NuGet package:
install-package Polly
Step 2: Define Polly policies:
Retry policy
A basic retry policy can be defined as follows:
builder.Services.AddSingleton<Polly.Retry.AsyncRetryPolicy>(x => {
var policy = Policy.Handle<Exception>().WaitAndRetryAsync(
retryCount: 3,
sleepDurationProvider: (retryCount) => TimeSpan.FromMilliseconds(500 * retryCount),
onRetry: (result, timeSpan, retryCount, context) => {
Log.Logger.Information($"Begin {retryCount}th retry for correlation {context.CorrelationId} with {timeSpan.TotalSeconds} seconds of delay");
});
return policy;
});
Simply retrying the same request again, in constant intervals, might not be optimal, and may even, in some scenarios bring more load to the application.
A more advanced approach is using exponential backoff, which allows retires to be made at progressively longer intervals.
Here’s an example of such policy:
builder.Services.AddSingleton<Polly.Retry.AsyncRetryPolicy>(x => {
int firstRetryDelay = 35;
int retryCount = 10;
var jitteredDelay = Backoff.DecorrelatedJitterBackoffV2(TimeSpan.FromMilliseconds(firstRetryDelay), retryCount);
var policy = Policy.Handle<Exception>()
.WaitAndRetryAsync(jitteredDelay);
return policy;
});
Circuit Breaker
The following is an example of how you can setup an async circuit breaker policy:
builder.Services.AddSingleton < Polly.CircuitBreaker.AsyncCircuitBreakerPolicy > (x => {
var policy = Policy.Handle<Exception>()
.CircuitBreakerAsync(exceptionsAllowedBeforeBreaking: 2,
durationOfBreak: TimeSpan.FromSeconds(2),
onBreak: (msg, timeSpan) => {
Log.Logger.Warning("Circuit breaker in now open");
// do some logic
},
onHalfOpen: () => {
Log.Logger.Warning("Circuit breaker moved to half open");
// do some logic
},
onReset: () => {
Log.Logger.Warning("Resetting circuit breaker");
// do some logic
});
return policy;
Fallback Policy
Policy<String>
.Handle<Exception>()
.Fallback(
fallbackAction: /* Demonstrates fallback action/func syntax */ () => {
return "Please try again later";
},
onFallback: e => {
Log.Logger.Debug("Fallback catches eventually failed with: " + e.Exception.Message);
}
);
Network timeout policy
var timeoutPolicy = Policy.TimeoutAsync<string>(timeoutInSeconds, TimeoutStrategy.Pessimistic,
onTimeoutAsync: (context, timespan, _, _) => {
Log.Logger.Error("Timeout during execution of the call");
return Task.CompletedTask;
});
Policy Wraps
You can chain policies together, to make your application handle failure even better.
AsyncPolicyWrap<string?> CreatResilientPolicies()
{
int maxRetries = 2;
int breakCurcuitAfterErrors = 6;
int keepCurcuitBreakForMinutes = 1;
int timeoutInSeconds = 3;
// Specify the type of exception that our policy can handle.
// Alternately, we could specify the return results we would like to handle.
var policyBuilder = Policy<string?>
.Handle<Exception>();
// Fallback policy:
var fallbackPolicy = policyBuilder
.FallbackAsync((calcellationToken) =>
{
// In our case we return a null response.
Log.Logger.Information($"{DateTime.Now:u} - Fallback null value is returned.");
return Task.FromResult<string?>("Some default value");
});
// Wait and Retry policy:
// Retry with exponential backoff
var retryPolicy = policyBuilder
.WaitAndRetryAsync(maxRetries, retryAttempt =>
{
var waitTime = TimeSpan.FromSeconds(Math.Pow(2, retryAttempt));
Log.Logger.Information(
"{DateTime.Now:u} - RetryPolicy | Retry Attempt: {retryAttempt} | WaitSeconds: {waitTime.TotalSeconds}");
return waitTime;
});
return Policy.WrapAsync(fallbackPolicy, retryPolicy);
}
var _resilientPolicies = CreatResilientPolicies();
builder.Services.AddSingleton(_resilientPolicies);
Step 3 – Inject and use
await _resiliencePolicies.ExecuteAsync(async () => await doSomething())).ConfigureAwait(false);Conclusion
We just saw how to create Polly policies and use them separately, or combined together to make our application more resilient, but your application should not depend on Polly to handle all failures and should have proper error and fault handling mechanisms as well, for other failure cases as well.
That is it for this time,
Thank you for stopping by!
Cover image by Lutz Peter from Pixabay