
Featured image by Gerd Altmann from Pixabay
Intro
In this post, we are going to review and provide a brief explanation of the 12 principles of building Software-as-a-Service applications. The method was put together by Adam Wiggin in 2011, originally called “The 12 Factor App”, and is available here.
To cite directly from 12factor.net site, let’s review what this methodology is trying to achieve:
Use declarative formats for setup automation, to minimize time and cost for new developers joining the project;
This basically refers to a way to ease automation setup when setting up new services, or when a new member joins the team.
Have a clean contract with the underlying operating system, offering maximum portability between execution environments;
The idea here is not to be tight to a certain operating system or specific platform but rather decoupled as much as possible.
Are suitable for deployment on modern cloud platforms, obviating the need for servers and systems administration;
As some might argue this is not a critical point since in some cases the business will deploy the application on-premise. But even on-premise deployment can also be based on a “cloud” service pack (On-Premise Cloud).
Minimize divergence between development and production, enabling continuous deployment for maximum agility;
It’s always beneficial that the development environment be as similar as possible to the production environment. This helps even more when investigating defects or bugs.
And can scale up without significant changes to tooling, architecture, or development practices;
Scaling is considered one of the key properties and requirements of a modern application today, whether deployed on the cloud or not.
The 12 Factors
1. Codebase
One codebase tracked in revision control, many deploys
This principle states that all the code and assets related to an application is located in a single repository, this includes source code files, image assets, automation scripts, deployment script and so on. The repository should be accessible to all the teams working on the application development, testing, and release, and any other team that might need access to ensure the application is released.
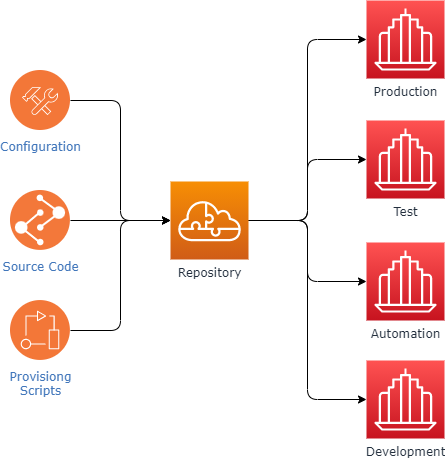
If the project has multiple repositories, then it should be considered a distributed system, a good example would be microservices.
2. Dependencies
Explicitly declare and isolate dependencies
This principle states that only the code which is relevant and unique to the application should be stored in the repository. External dependencies, like DLL files, JAR files, or Node.js packages should be referenced in a dependency manifest and loaded on a need basis, in development, testing, automation, or production runtime. We should avoid storing external artifacts and dependencies along with the source code in the same repo.
The standard build tools we have today, along with package managers like NuGet and NPM, already provide a good solution for this.
We should also keep in mind that dependencies are not only DLL files or packages, but they can also be other services, database connections, etc…
Some examples of managing these types of dependencies are chef and Kubernetes.
3. Config
Store config in the environment
The config principle states that configuration details should be stored in the runtime environment and injected into the application as environment variables and environment settings. An example of such a case is stating configuration settings in a docker-compose.yml file.
The benefit of doing this separation of configuration from application logic is that we can apply configuration according to the relevant deployment environment.
4. Backing Services
Treat backing services as attached resources
A backing service is any service the application consumes over the network as part of its normal operation.
This principle states that we should treat any backing service as an attached resource that is easily interchangeable. So for example, the application should be able to easily switch from one database to another, without making any code source code change, other than configurations, like address, credentials, and so on.
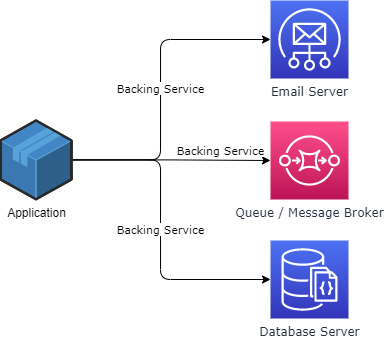
Some examples of attached resources are database servers, message broker and email servers.
5. Build, Run, Release
Strictly separate build and run stages
This principle breaks down the deployment process of an application into three stages, each can be instantiated at any time.
- Build – Converting to source that exists in the application repository in artifacts.
- Release – Apply the configuration setting to the built artifact.
- Run – Running the application on the provisioned environment.
Since each stage is strictly separated from the other, it can be executed separately without breaking the other stages.
6. Processes
Execute the app as one or more stateless processes
This principle here is that the running application should be a collection of stateless processes. Meaning no process should keep track of the state of another process, and no process should keep track of information like session status. Hence, the 12-factor application processes are stateless and share nothing.
7. Port Binding
Export services via port binding
The idea of this principle is to make sure that a service is visible and reaching to other services via port binding. For example, an application can be running as a Docker container, exposing a certain port for accepting requests from other services. Once an application exposes a port, it can become a backing service for another application or service.
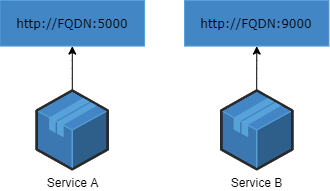
8. Concurrency
Scale out via the process model
The concurrency principle states that we should architect and organize the application processes based on the type of work they do, i.e, according to their purpose, this way, they can be scaled up or down easily, on-demand. The idea here is that when the application needs to scale in order to handle more workload, we can add more process instances, rather than adding more “machine power” like RAM or CPU.

9. Disposability
Maximize robustness with fast startup and graceful shutdown
The disposability principle states that a process should start fast, and shutdown gracefully. Fast startup is important, especially when scaling the application up, as it ensures the new instance is ready to process work in a very short time.
Graceful shutdown is about leaving the system in a correct state in case of sudden or intentional process shutdown. For this to happen we need to make sure that our code supports this, with proper clean-ups of database connections, for example, the release of unmanaged resources, and so on.
10. Dev/Prod Parity
Keep development, staging, and production as similar as possible
This principle states that we should keep the gap between development and production as minimal as possible. The gaps can happen since the developer are using a smaller or lighter version of a database for example than the one deployed in production, or using some local caching library on their machine while production use memcached, and so on. The twelve-factor developer resists the urge to use different backing services between development and production, as these differences might crop up incompatibilities and sometimes problems in code when executed in a test or the production environment.
11. Logs
Treat logs as event streams
The principle recommends sending the logs data as streams to standard output. They can be consumed by other applications, rather ran writing to a log file or managing log files locally or centrally.
Log routing should not be the concern of the application, since once the logs are written the standard output. Tools like Logdrainer (ELK) can be used to gather and route logs, and later have the logs available for analysis and querying (for example in Kibana). An example of logging flow would be:

Logger – The actual logger library
Log Event – The event and log data
Log Stream – Un-buffered, time ordered stream of event logs
Log Ship / Transport – The application, plugin or transport mean that send the log data to a sink
Log Sink – The log final stop. Can be file, console, some indexing engine and monitoring system
12. Admin Processes
Run admin/management tasks as one-off processes
The principle states that administrative tasks should be run from relevant processes, and that these process ship with the application. The admin tasks source code should exist in the same code repository as the application, built and shipped with the application, but are executed separately.
Ensuring that these admin process, can be executed as one-off runs, and can have scheduled automated execution (if needed).